计算机领域中有诸多有意思的东西可以把玩,在这儿且看看分布式存储。
集群文件系统在某些场景下又可以称作网络文件系统、并行文件系统,在70年代由IBM提出并实现原型。
有几种方法可以实现集群形式,但多数仅仅是节点直连存储而不是将存储之上的文件系统进行合理“分布”。分布式文件系统同时挂载于多个服务器上,并在它们之间共享,可以提供类似于位置无关的数据定位或冗余等特点。并行文件系统是一种集群式的文件系统,它将数据分布于多个节点,其主要目的是提供冗余和提高读写性能。
共享磁盘(Shared-disk)/Storage-area network(SAN)
从应用程序使用的文件级别,到SAN之间的块级别的操作,诸如权限控制和传输,都是发生在客户端节点上。共享磁盘(Shared-disk)文件系统,在并行控制上做了很多工作,以至于其拥有比较一致连贯的文件系统视图,从而避免了多个客户端试图同时访问同一设备时数据断片或丢失的情况发生。其中有种技术叫做围栏(Fencing),就是在某个或某些节点发生断片时,集群自动将这些节点隔离(关机、断网、自恢复),保证其他节点数据访问的正确性。元数据(Metadata)类似目录,可以让所有的机器都能查找使用所有信息,在不同的架构中有不同的保存方式,有的均匀分布于集群,有的存储在中央节点。
实现的方式有SCSI,iSCSI,AoE,FC,Infiniband等,比较著名的产品有Redhat GFS、Sun QFS、Vmware VMFS等。
分布式文件系统
分布式文件系统则不是块级别的共享的形式了,所有加进来的存储(文件系统)都是整个文件系统的一部分,所有数据的传输也是依靠网络来的。
它的设计有这么几个原则:
- 访问透明 客户端在其上的文件操作与本地文件系统无异
- _位置透明 _ 其上的文件不代表其存储位置,只要给了全名就能访问
- 并发透明 所有客户端持有的文件系统的状态在任何时候都是一致的,不会出现A修改了F文件,但是B愣了半天才发现。
- _失败透明 _ 理解为阻塞操作,不成功不回头。
- 异构性 文件系统可以在多种硬件以及操作系统下部署使用。
- 扩展性 随时添加进新的节点,无视其资格新旧。
- 冗余透明 客户端不需要了解文件存在于多个节点上这一事实。
- 迁移透明 客户端不需要了解文件根据负载均衡策略迁移的状况。
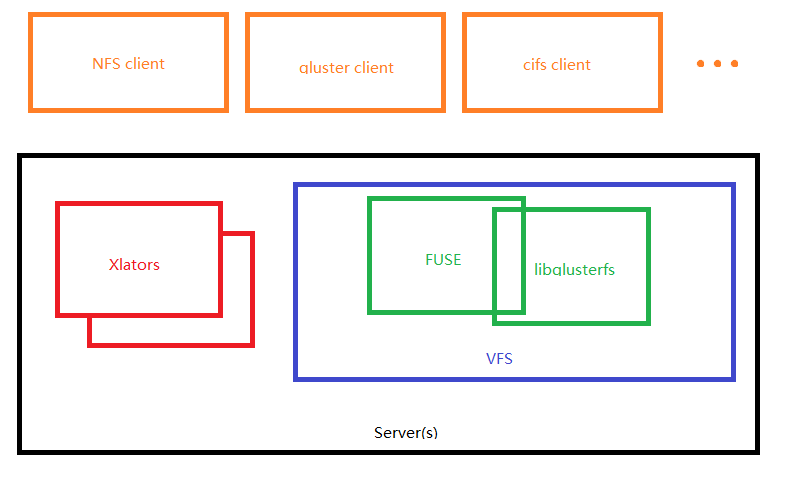
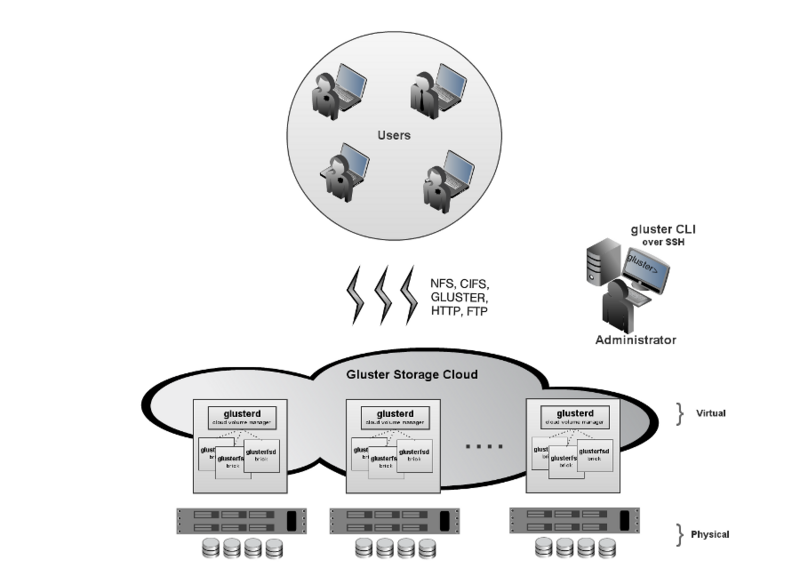
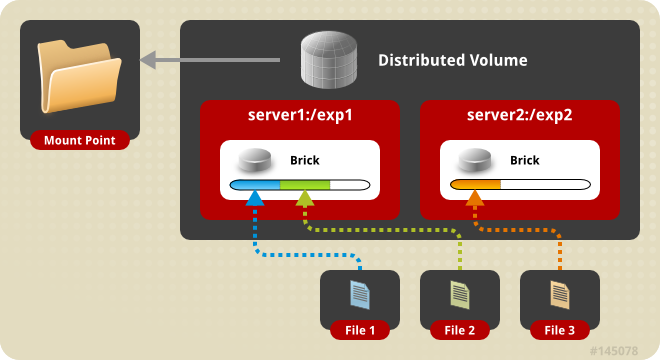
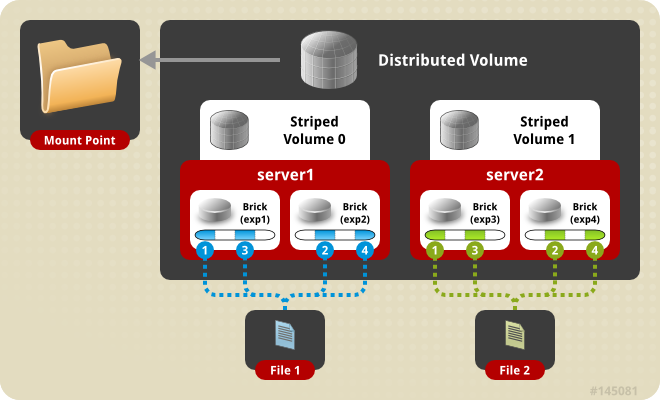
实现的方式有NFS、CIFS、SMB、NCP等,比较著名的产品有Google GFS、Hadoop HDFS、GlusterFS、Lustre等。