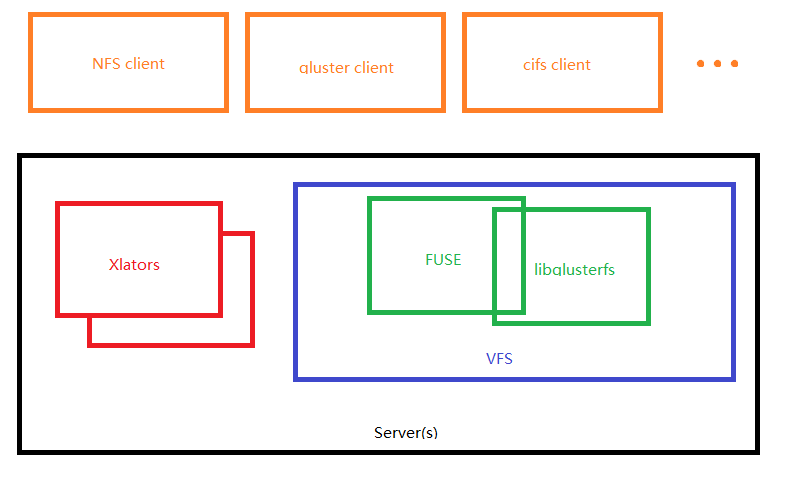
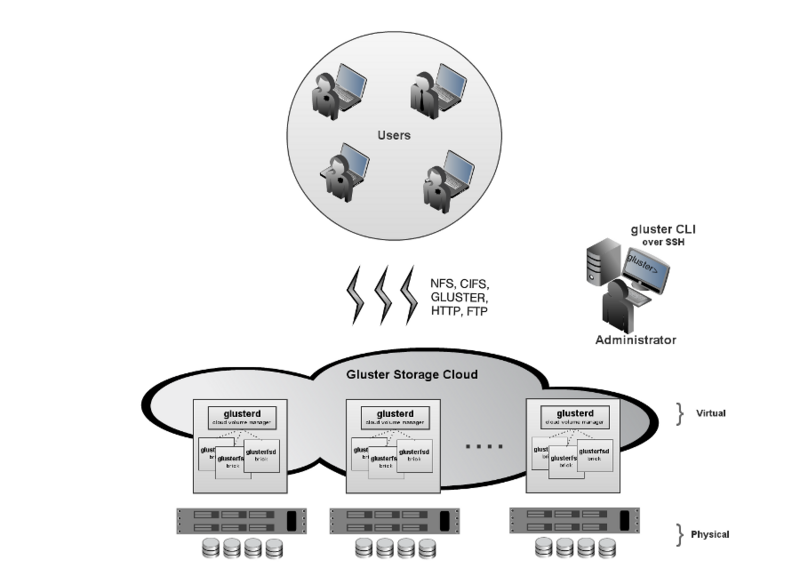
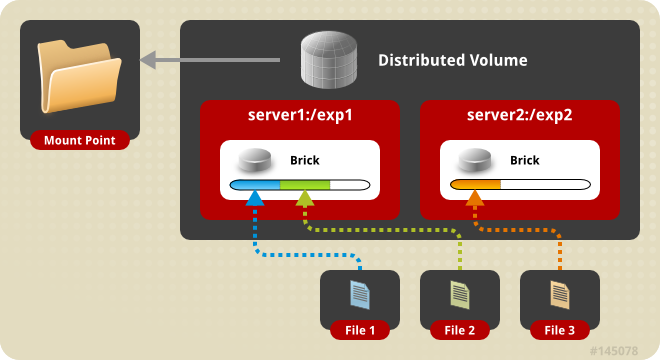
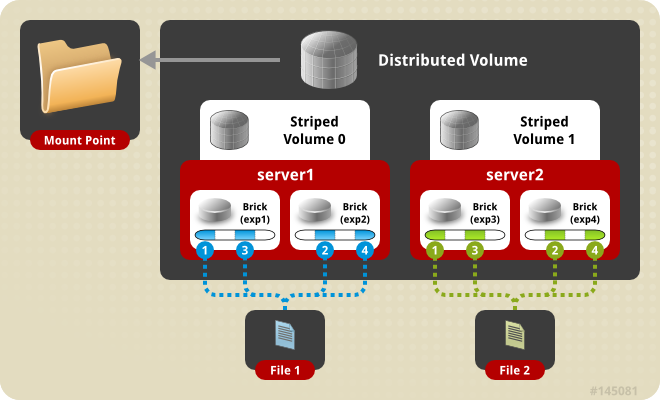
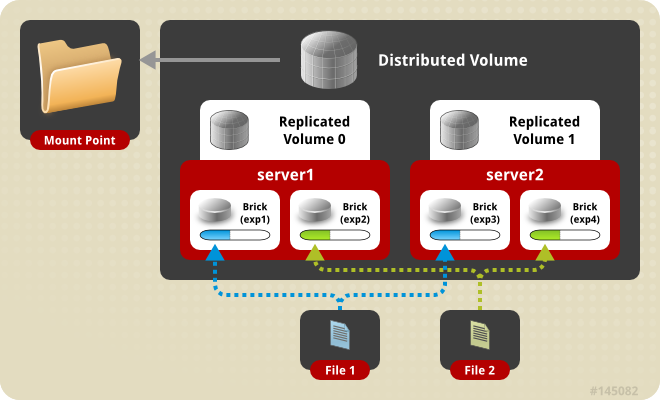
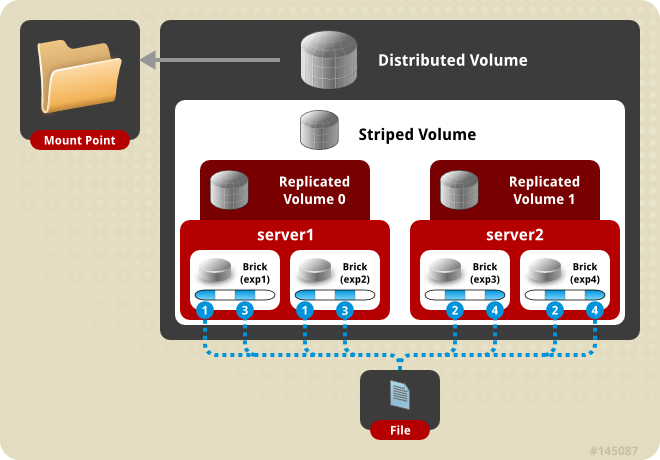
既然要搭建一个稳健的基础,那么glusterfs在此使用distributed striped replicated方式,这里使用4台预装CentOS 6(SELINUX设置为permissive)的机器。

鉴于笔者所在环境中暂时没有配置独立的DNS,此处先修改hosts文件以完成配置(每台机器上都如此设置):
[epel] name=Extra Packages for Enterprise Linux 6 - $basearch
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch failovermethod=priority enabled=1 gpgcheck=0 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
[glusterfs-epel] name=GlusterFS is a clustered file-system capable of scaling to several petabytes. baseurl=http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/epel-\(releasever/\)basearch/ enabled=1 skip_if_unavailable=1 gpgcheck=1 gpgkey=http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/pub.key
[glusterfs-noarch-epel] name=GlusterFS is a clustered file-system capable of scaling to several petabytes. baseurl=http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/epel-$releasever/noarch enabled=1 skip_if_unavailable=1 gpgcheck=1 gpgkey=http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/pub.key
[glusterfs-source-epel] name=GlusterFS is a clustered file-system capable of scaling to several petabytes. - Source baseurl=http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/epel-$releasever/SRPMS enabled=0 skip_if_unavailable=1 gpgcheck=1 gpgkey=http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/pub.key
每一个节点都可以看做gluster server,安装xfs用户空间工具:
假如每台机器除系统盘之外都有2块1T SATA硬盘。 对其进行分区,创建逻辑卷,格式化并挂载:
n p 1
w EOF
直接使用物理盘:
或者使用逻辑卷:
为什么要用XFS? XFS具有元数据日志功能,可以快速恢复数据;同时,可以在线扩容及碎片整理。其他文件系统比如EXT3,EXT4未做充分测试。
在其中任何一台机器上,比如gs2.example.com,执行:
peer probe gs1.example.com peer probe gs2.example.com
添加brick至volume,合理调整砖块顺序:
volume create gluster-vol1 stripe 2 replica 2 gs1.example.com:/gluster_brick0 gs1.example.com:/gluster_brick1 gs2.example.com:/gluster_brick0 gs2.example.com:/gluster_brick1 gs3.example.com:/gluster_brick0 gs3.example.com:/gluster_brick1 gs4.example.com:/gluster_brick0 gs4.example.com:/gluster_brick1 force volume start gluster-vol1 volume status Status of volume: gluster-vol1 Gluster process Port Online Pid
Brick gs1.example.com:/gluster_brick0 49152 Y 1984 Brick gs1.example.com:/gluster_brick1 49153 Y 1995 Brick gs2.example.com:/gluster_brick0 49152 Y 1972 Brick gs2.example.com:/gluster_brick1 49153 Y 1983 Brick gs3.example.com:/gluster_brick0 49152 Y 1961 Brick gs3.example.com:/gluster_brick1 49153 Y 1972 Brick gs4.example.com:/gluster_brick0 49152 Y 1975 Brick gs4.example.com:/gluster_brick1 49153 Y 1986 NFS Server on localhost 2049 Y 1999 Self-heal Daemon on localhost N/A Y 2006 NFS Server on gs2.example.com 2049 Y 2007 Self-heal Daemon on gs2.example.com N/A Y 2014 NFS Server on gs2.example.com 2049 Y 1995 Self-heal Daemon on gs2.example.com N/A Y 2002 NFS Server on gs3.example.com 2049 Y 1986 Self-heal Daemon on gs3.example.com N/A Y 1993
There are no active volume tasks
volume info all gluster volume info all
Volume Name: gluster-vol1 Type: Distributed-Striped-Replicate Volume ID: bc8e102c-2b35-4748-ab71-7cf96ce083f3 Status: Started Number of Bricks: 2 x 2 x 2 = 8 Transport-type: tcp Bricks: Brick1: gs1.example.com:/gluster_brick0 Brick2: gs1.example.com:/gluster_brick1 Brick3: gs2.example.com:/gluster_brick0 Brick4: gs2.example.com:/gluster_brick1 Brick5: gs3.example.com:/gluster_brick0 Brick6: gs3.example.com:/gluster_brick1 Brick7: gs4.example.com:/gluster_brick0 Brick8: gs4.example.com:/gluster_brick1
当用glusterfs-fuse挂载时,客户端的hosts文件里需要有gluster server中的任一节点做解析:
127.0.0.1 localhost.localdomain localhost ::1 localhost6.localdomain6 localhost6
192.168.1.81 gs1.example.com
安装glusterfuse,将gluster卷作为glusterfs挂载,并写入1M文件查看其在各砖块分配:
在四台服务端分别查看:
[root@gs1 ~]# ls -lh /gluster_brick* /gluster_brick0: total 1.0M -rw-r--r--. 2 root root 512K Apr 22 17:13 a.img -rw-r--r--. 2 root root 512K Apr 22 17:13 d.img /gluster_brick1: total 1.0M -rw-r--r--. 2 root root 512K Apr 22 17:13 a.img -rw-r--r--. 2 root root 512K Apr 22 17:13 d.img
[root@gs2 ~]# ls -lh /gluster_brick* /gluster_brick0: total 1.0M -rw-r--r--. 2 root root 512K Apr 22 17:13 a.img -rw-r--r--. 2 root root 512K Apr 22 17:13 d.img /gluster_brick1: total 1.0M -rw-r--r--. 2 root root 512K Apr 22 17:13 a.img -rw-r--r--. 2 root root 512K Apr 22 17:13 d.img
[root@gs3 ~]# ls -lh /gluster_brick* /gluster_brick0: total 1.0M -rw-r--r--. 2 root root 512K Apr 22 17:13 b.img -rw-r--r--. 2 root root 512K Apr 22 17:13 c.img /gluster_brick1: total 1.0M -rw-r--r--. 2 root root 512K Apr 22 17:13 b.img -rw-r--r--. 2 root root 512K Apr 22 17:13 c.img
[root@gs4 ~]# ls -lh /gluster_brick* /gluster_brick0: total 1.0M -rw-r--r--. 2 root root 512K Apr 22 17:13 b.img -rw-r--r--. 2 root root 512K Apr 22 17:13 c.img /gluster_brick1: total 1.0M -rw-r--r--. 2 root root 512K Apr 22 17:13 b.img -rw-r--r--. 2 root root 512K Apr 22 17:13 c.img
至此,所有配置结束,下一篇说一下使用以及部分trick。